The RADDD Stack
In this article I will describe how to produce an all local data platform using the RADDD data stack (everyone’s talking about it, promise), the stack consists of 4 layers that work together to provide a fast, tunable platform that can scale to production seamlessly.
I will also provide a reference implementation in a follow up article that will first perform some simple SQL transformations of a source dataset before getting down into Python to render a years worth of audio in two days on a laptop.
Stack
Here’s a quick diagram to show how everything ties together
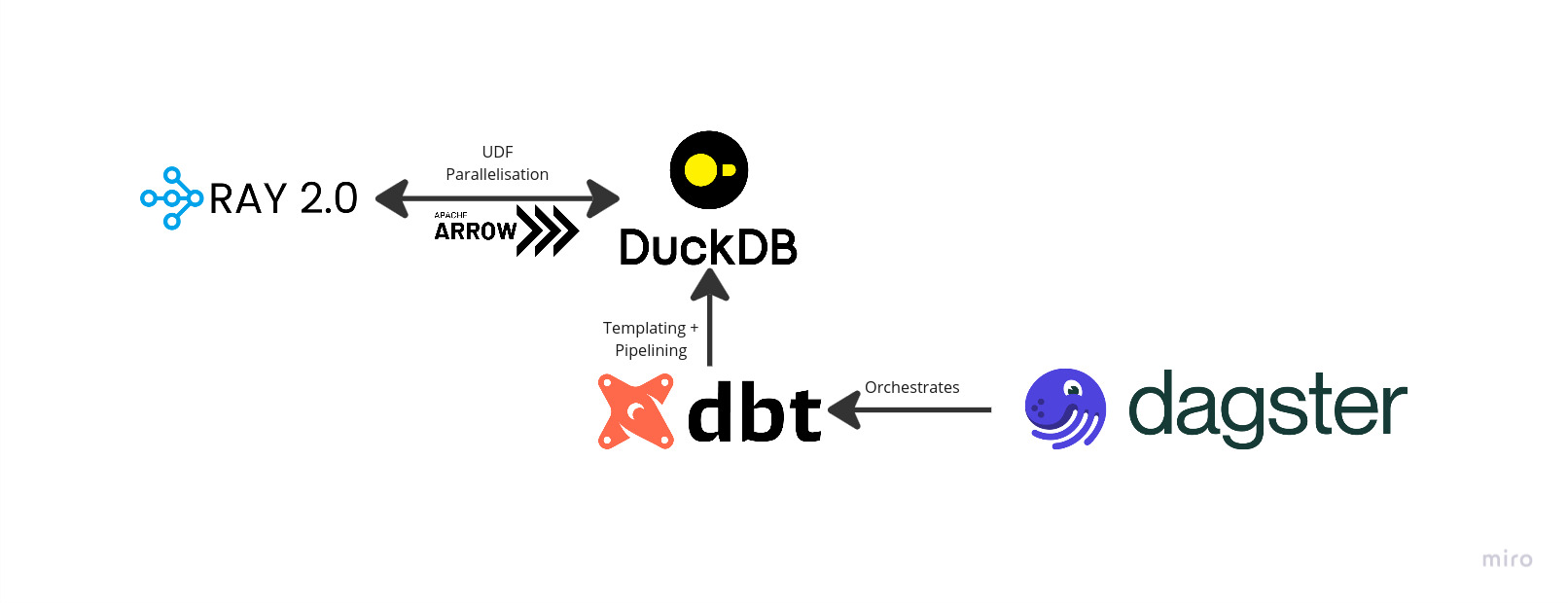
Ray
Ray allows us to scale arbitrary Python computations and provides an extremely simple interface to trivially parallelise those annoying jobs that we cant do in our database management system (DBMS). Crucially Ray will allow scaling of compute heavy tasks beyond the level of your laptop if the need were ever to arise, but at the same time it still runs brilliantly even on a single machine.
Arrow
Arrow is an interchange format that uses a columnar memory structure (more on that later) that allows for zero-copy transfer of data between processes. On a high level, this is achieved by passing a pointer around, rather than the entire data structure. This saves a lot of time spent copying memory needlessly since, critically, these pointers are shared between threads, and so can safely be passed between process boundaries (unlike for eg a Pandas dataframe that would need to be copied in this situation)
DuckDB
DuckDB is a vector database optimized for fast online analytical processing (OLAP) operations. Buzzwords aplenty, let’s unpack that. A vector database is one in which the query engine will read the column as a list (i.e vector) of values that are all sequential in memory, this make it a columnar format, like Arrow. Online transaction processing (OLTP) databases, in contrast, store data in a row-major fashion which assumes the full row will want to be read into memory, this results in many CPU cache misses when performing computations on entire columns.
DuckDB is also compatible with many other database technologies, so not only is it useful for analytics, is also useful as a data engineering tool to facilitate moving data from point a to point b. For instance, you can attach to an SQLite (or Postgres now) DB and write your outputs there, or to a Parquet file, in your local or any FSSpec compatible filesystem.
Finally DuckDB has tight Python integrations, allowing for wizardry where you can select various data frames within scope by name and run arbitrary computations on them, or run Python functions over either the entire vector or value by value. Unfortunately this functionality is currently limited to a single thread and does not like to be involved with the multiprocess library and there is some time until there is a DuckDB solution. In the meantime we could use Ray to run operation in parallel. Since both DuckDB and Ray are tightly integrated with Arrow, this whole pipeline should incur no or minimal serialization overhead
DBT
DBT is utilised to build pipelines, this can take the form of either Python or SQL models. DBT integrates extremely well with DuckDB and the adapter is extremely configurable allowing you to setup DuckDB exactly how you need it to get data where it needs to be. DBT is essentially a collection of template SQL queries and Python functions that define a computation graph.
The DuckDB adapter is one of few that allow for Python models, but since DuckDB is just running locally on your system it’s easy to just use your local environment to perform this work. The adapter delivers the data as a DuckDBPyRelation object, which can easily be used in downstream Python computation in that will be demonstrated in the implementation.
Dagster
Beyond a certain scale some of these transforms will overflow the bounds of your memory, DuckDB is getting better at handling that but it’s still a big performance hit to try to process the entire database in a single query. So, it will be necessary to break some of these tasks up into more manageable chunks or partitions. This creates the problem of managing the partitions that have been created and ensuring all dependent data is in the right place. For this we turn to Dagster, which we is used to as the orchestrator in the RADDD stack.
In Dagster, a software-defined asset is a concept that represents a piece of data or a computation that produces data within the system. It allows you to define, schedule, partition and monitor data workflows and will help to make sure all the data is processed and help you to track that.
Dagster integrates easily with DBT and allows you to use a DBT project to automatically define software-defined assets in Dagster, and it is a small amount of configuration to facilitate partitioning.
Implementation
For a reference implementation we will select a use case that will demonstrate a range of transforms some of which can be achieved directly in SQL and some which need more complex transforms which require a more general purpose programming language to solve.
In this case we take a somewhat pre-processed dataset derived from the Lakh MIDI dataset. The source dataset has been processed into a list of notes, represented as track_id, start_time, duration, velocity and note. start_time and duration are floats represented in beats (meaning we would need to choose a BPM to calculate their real time), velocity represents how hard the note was struck, while note represents the MIDI pitch number both of these are 7-bit integers i.e 128 values.
The task is to extract all 4-beat phrases from the notes and then render them into FLAC using a synthesizer. Extracting the list of 4-beat phrases is a simple transform involving some simple math and grouping. Rendering audio and transcoding to FLAC will require a bit more, for that we follow a running theme of this site and use the Yamaha DX7 to synthesize the audio, and without a cloud attached farm of them to use for the task we fall back to Dexed, a free DX7 emulator, this is hosted in a Python function using Pedalboard from Spotify
One of the requirements of this project is for it to run on a decent laptop, 16-cores and 32Gb memory in this case but the architecture will allow this to be tunable. You would quickly run out of memory if you tried to do this all at once, so the implementation also demonstrates partitioning and producing results in batches.
A full write-up and the code for the implementation is available here and the code is at github.com/Nintorac/raddd_dx7_stack
Beware! This is running in a Google Cloud Run and can be slow on the first load, please be patient! For a random sample refresh on this page dx7.nintoracaudio.dev/phrases/0, or you can choose a specific sample by setting a number greater than 0 in the above URL. eg dx7.nintoracaudio.dev/phrases/99
Result
How does it perform? Well the default number of partitions was picked to run on my 16 thread, 32GB memory machine and it can produce a single partition in 3m20s on average. For the entire 800 partitions that will take about 1.8 days to produce.
Each partition has exactly 8521 phrases (which is a bit suspicious since the partition is based on the midi_id, but lets ignore that). Each phrase is 5 seconds of audio rendered which results in a total rendered time of 11.8 hours which gives a real-time factor (RTF) of 212.4 which seems pretty good.
For the entire dataset this is 11.8 hours * 800 which comes to just over 1 year of audio and that’s only 1/8th of the data available in Lakh.
Conclusions
We’ve demonstrated a lightweight fast and scaleable data stack that can run on a laptop, it is left as a future exercise to see how gracefully it will scale to larger workloads but that may come up if I feel motivated.
While there are a lot of tools and concepts to grok here they come together to provide a way to efficiently write complex pipelines. There is minimal boilerplate and you can just focus on writing the business logic. Things like IO and data storage are handled automatically, work by default and are configurable when the need arises. eg We can write jobs to preload data into sqlite, Postgres, Parquet using just DuckDB.
There’s a lot more to figure out here, automatic UDF registration, how to define the business logic in its own library and have DBT reference that directly but its a rich and versatile stack and I hope to see if anyone can show any cool applications!