A case study on deploying an ML model in the cloud
How a machine learning model was served to \(25,000\) users for only $2!
Introduction
This article will go over the tools and services used to deploy the website www.thisdx7cartdoesnotexist.com. The website was a first run at releasing to the world a machine learning model that was developed to generate patches for the Yamaha DX7, and while there won’t be details in this article about what that is or why it matters, there will be details about how the model was successfully served at scale and didn’t fall prey to the slashdot effect after reaching top three in Hacker News!
There were two main goals of this deployment a) the site had to be fairly responsive, meaning preferably sub-second request times and b) everything had to be done as cheaply as possible, preferably for free.
Components
To motivate the deployment description we will first describe the separate parts required to facilitate
The website is fairly simple and is made up of three parts. The first is the frontend which greeted users and allowed them to generate novel and unique DX7 patches at the push of a button, as well as giving a little information about the how, what and the why. Second, the backend which is a simple one method Flask endpoint running a PyTorch model.
Frontend
The frontend was developed using Jeykll, it’s main use is as a simple blogging platform, however using one of the many themes available it can take on a multitude of forms. In this case a theme was found that created a simple front-page that was then modified to include an FAQ section and spiced up with various CSS and HTML effects found around the internet to give it that 80’s vibe, inline with the subject of the site.
Jekyll was chosen as it compiles down to a simple static website which can be deployed super easily with minimal infrastructure and cost. Due to lack of frontend development experience this was probably the most painful part of the system to develop but the final product did the job. For those that haven’t seen it, here’s a screen cap.

Backend
The backend consists of a simple flask server with a single endpoint. Flask was chosen for two simple reasons; the model was written in PyTorch and the model was initially to be deployed using a Google Cloud Functions. More on these later.
The model itself was a feed-forward attention decoder, the model performed attention over \(155\) parameters and had 3 layers giving it a computational complexity of around \(\mathcal{O}(3\times155^2)\) which is simple enough to run on a CPU in around 200ms. A DX7 patch consists of 32 such parameters sets so the model needed to be run a total of \(32\) times to generate the full patch set, luckily the runtime doesn’t scale linearly due to PyTorch optimisations!
Deployment
Model Serving
Now that the application has been motivated let’s get into the deployment. The initial plan was to run the model using Google Cloud Functions and the Jekyll app with a GCP bucket, at the time we only had a vague awareness of the products in this space and we were entirely unaware of their pros and cons. All we knew was that GCS was dirt cheap to run a static site through and Cloud Function’s were reasonably priced, charging only by the 100ms, and not requiring infrastructure maintenance.
Having already trained the model, the first item on the agenda was to create the cloud function to serve it. The code for that was really basic, just load the model, sample some latent values, generate the parameter values, pack it into a format that the DX7 can understand and send to the user. It looked a little like this.
def generate(request):
"""Patch generation function.
Args:
request (flask.Request): The request object.
<http://flask.pocoo.org/docs/1.0/api/#flask.Request>
Returns:
The the syx patch file for a yamaha DX7
"""
global model
# load the model if this is a cold start
if model is None:
model = InferenceWorker('hasty-copper-dogfish', 'dx7-vae', with_data=False).model
# sample latent from prior N(0,1)
z = torch.randn(32, 8)
# decode samples to logits
p_x = model.generate(z)
# Get most likely
sample = p_x.logits.argmax(-1)
# convert pytorch tensors to syx
msg = dx7_bulk_pack(sample.numpy().tolist())
# Write to file and send
with NamedTemporaryFile('wb+', suffix='.syx') as f:
mido.write_syx_file(f.name, [msg])
# as_attachment in order to prompt for download
# attachment filename to give it a better name
# cache_timeout=-1 so the user gets a new patch each time
return send_file(f.name,
as_attachment=True,
attachment_filename=f'dx7_{uuid()}.syx',
cache_timeout=-1
)
Since Cloud Functions can only package code and dependencies the model weights would need to be downloaded whenever the function was called from a cold start. The InferenceWorker class handles this automatically by downloading weights from a known location.
Originally this was planned to be a Google Cloud Storage bucket, however with a weights file totalling \(60\)Mb this would quickly rack up costs and although it wasn’t envisaged that there would be too much fervour over this work, horror stories like that of AI Dungeon 2 combined with the lack of 0’s in the bank prompted further research. In the end it was decided a separate weights repository would do the job for the wonderful price of FREE! Thanks Github!
With the cloud function in place and the weights being loaded from their repository everything was ready to move onto hosting the static frontend…except no, it was not quite that simple. With this setup the unfortunate side effect was that each invocation of the cloud function from a cold start would result in an 8-second delay as the function downloaded the weights, this was unacceptable as most users would assume something was broken after two and leave the site.
The initial idea for a workaround was to encode the weights into a Python list and then on each cold-start write this list to a file and load the file off disk, gross. Wanting to avoid that idea at all costs a little more research was conducted until finally Google Cloud Run was discovered.
Cloud Run is pretty similar to Cloud Functions, i.e it charges by the 100ms and doesn’t require any manual scaling. However, instead of just uploading code and dependencies, a docker container is used instead. Great, so the weights could be baked into the Docker container and then as soon as the endpoint was hit the weights would be available. Even better, it was a chance to flex with Docker! The cloud run setup was a breeze, only a few small additions to the Cloud Function code were needed and after deployment everything was working perfectly. Additionally as a side bonus of using Cloud Run it was now possible to set a custom domain for the endpoint which was not so simple with functions!
Frontend
Originally it was planned that the frontend would be hosted using a Google Cloud Storage bucket as this seemed like the easiest option. After building the site in Jekyll and uploading the static content to a bucket it was time to link up the domain at which point everything would be ready to go. Linking the domain was simple enough using Google Cloud DNS. However, it was quickly discovered that buckets would not allow https access for custom domains and in this day and age that was a necessity. To tell the truth, it is possible, unfortunately your average load balancer runs about \(\$20\) a month which flies in the face of the cheap.
The next idea was to have the flask server hosting the model also serve the Jekyll static content. Although this is probably technically possible the search results did not seem particularly helpful and so “we though na forget it, yo homes just use another container”, and so another container was cooked up (read stolen) that used Nginx to serve the content. Again this was hooked up to the DNS and everything was ready to go!

Preparing for full deployment
At this point the site was live and anyone who wanted to access it could, but the robots were told not to look because it wasn’t quite ready, and they didn’t, good robots.
Four things were required before public release and these were;
- Mitigate risk of a large infrastructure bill
- Stress test the site with simultaneous users
- Track the number of visitors
- Monetise the site
Budgets
To avoid a large bill a budget was created and set to $20 for the month. Then alarms were created that would send email alerts at 50%, 75%, 90% and 100% of the budget and a little peace of mind was enjoyed.
Stress testing
To stress-test the simplest method imaginable was used, the trusty terminal emulator Terminator was fired up, the screen was split many, many times, group broadcast was turned on to launch the requirest simultaneously and the commands wget https://www.thisdx7cartdoesnotexist.com/ and wget https://generate.thisdx7cartdoesnotexist.com were executed. Here is a dramatic reconstruction of the stress test.
There were memory errors in the containers so the memory limit was increased in the Cloud Run console. The test was re-run and everything ran successfully and completed in the sub \(2\) seconds mark.
Next, the maximum number of simultaneous instances of the generation endpoint was reduced and no further tests were run. This was a mistake.
Tracking
This was pretty easy, Google Analytics was added to the site which was accomplished by a simple setting provided by Jekyll. No worries!
Monetisation
Next AdSense was applied for, and many times it failed with an error saying the site could not be reached. This was surprising as no matter what was tried, the site could always be reached. After a while, it was discovered that the AdSense bot was respecting the robots.txt.
After allowing robots, ad sense came back saying the site lacked content and after taking the insult on the chin it was decided that there would be no ads.. and everyone rejoiced!
Retrospective
Going Live
One evening, once everything was in place the decision was made and the site was published on several subreddits. The analytics were obsessively followed and each new visitor was greeted with a little rush but after a few hours and less than 50 users the fear set in that no one liked the project and the last few weeks of toil had been for nought.
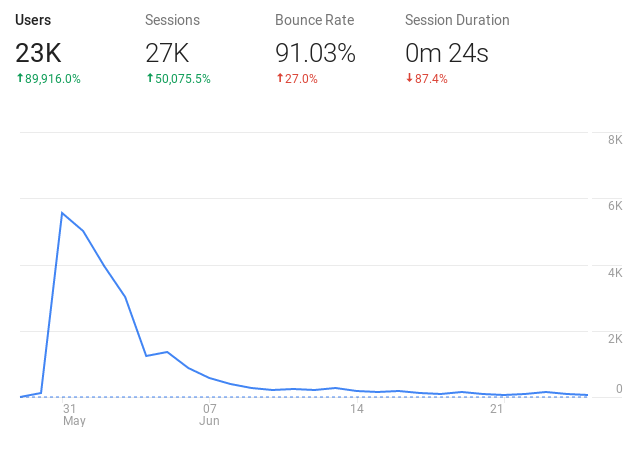
After waking up the next morning all those fears were allayed as there were currently over \(100\) active users. After a little digging, it was found that the site had been linked on Hacker News and had ranked quite nicely. The next week or so saw waves of new visitors as several articles were published. The analytics looks a little like this
Costs
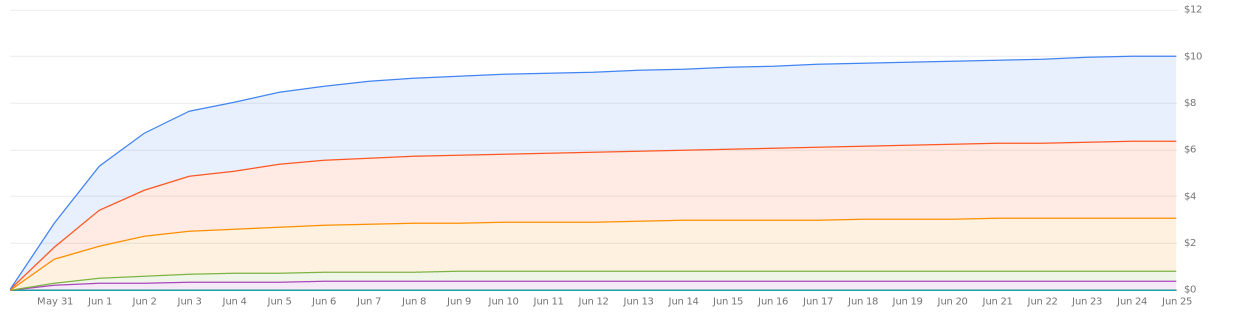
At the time of writing the site has had a total of \(25\)k users in total, this comes in at a total cost of around \(\$10\), of this \(60%\) was covered under Google Free Tier and so the remaining \(\$4\) ended up being the total cost for running the site for the last month. The following chart shows the cumulative total costs (including what does not need to be paid under Free Tier). Click the images to expand!
And here is the line by line breakdown of those costs
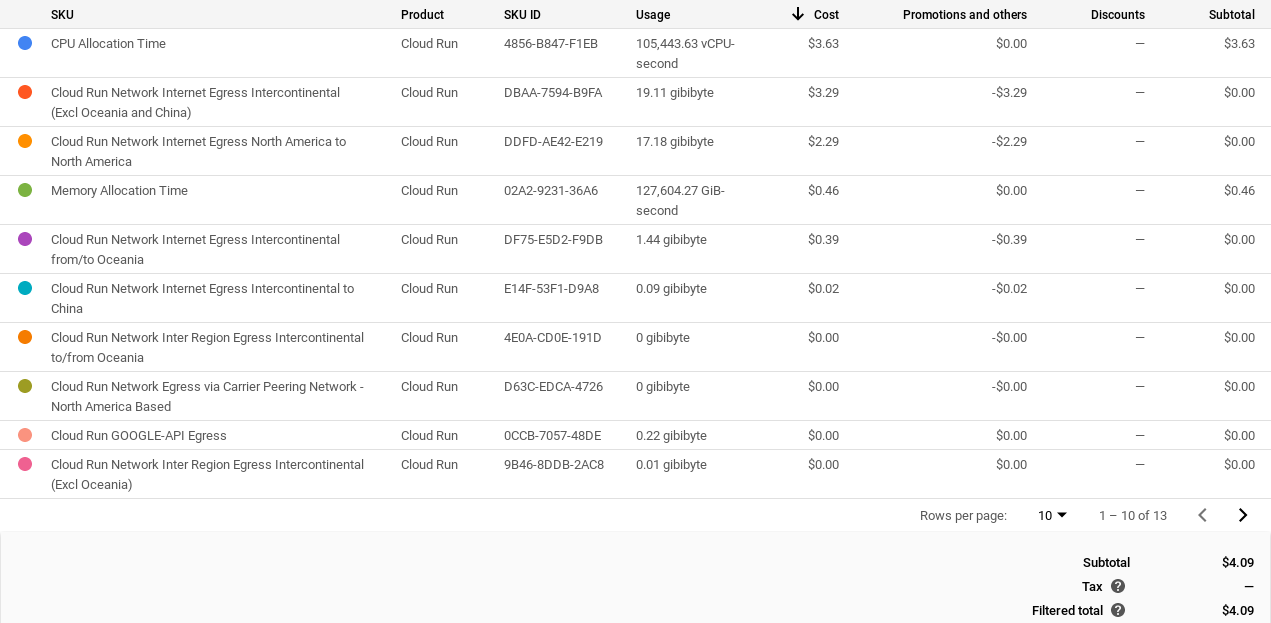
Note: the above costs are for both the front and back end Cloud Run services.
Hindsight
With hindsight there a few things that could be improved, first Weights and Biases seems like a much better place to host model weights than the somewhat hacky Github solution though further investigation is required into the feasibility of this.
Next, more stringent stress testing could have given a better indication of the performance of the site and might have led to optimising the generation endpoint. The average request time here was around 2 seconds which is a little longer than ideal but for the most part that hasn’t seemed to cause too much of an issue.
In the same vein of better operations management, iterating on the live deployment of the site was a bit of a hassle, so in the future it would be beneficial to set up a continuous integration system to handle that automatically, though maybe not worth it depending on the price point.
Finally, better monetisation techniques are needed that don’t rely on a robot deciding what is interesting. Luckily the Google Cloud free tier and credits have absorbed all of this cost up to this point but when it comes down to it, this model was incredibly cheap to train due to its low parameter count and small data complexity but for more interesting projects with higher data and model complexity those costs are going to balloon.
If you would like to discuss anything talked about in this article we have started a subreddit and urge all questions and commentary to be directed that way.
Congratulations if you made it to this point and thanks for reading, Stay creative from Nintorac Audio <3
Press
Oh and thanks for all the press! These are the ones found so far if you know of any that have been missed swing an email!
On a similar but not entirely related note, the patch endpoint was also included in this Max Device, so cool!